科研方向巡礼
程序员研究如何用计算机做事,我们则研究计算本身
← 左右滑动查看全图 · 点按任一方块进入该方向 →
本文涉及的 17 个科研方向(按出现顺序,括注首次介绍的章节)
- 半导体器件与先进工艺(第 3 章)
- EDA 与设计自动化(第 3 章)
- 光电子与硅光集成(第 4 章)
- 先进封装与异构集成(第 4 章)
- 处理器架构与编译系统(第 4 章)
- 可重构计算与 FPGA(第 4 章)
- 存算一体与近存计算(第 4 章)
- MEMS 与微纳传感器(第 5 章)
- 模拟与混合信号 IC(第 5 章)
- 射频与毫米波 IC(第 5 章)
- 功率半导体与宽禁带器件(第 5 章)
- 生物电子与脑机接口(第 5 章)
- 硬件安全与可信计算(第 5 章)
- AI 算法与系统(第 6 章)
- 具身智能(第 6 章)
- 类脑芯片(第 6 章)
- 量子计算与量子芯片(第 6 章)
用计算构建意义
一万年前,一个刚学会种地的人蹲在田埂上,盯着天发愁:明年会旱还是会涝?这头牛换多少粮食才不亏?隔壁那块地到底该归谁?第一次见她应该带多少布匹?
慢慢地,他学会了计算。他数雨水间隔的天数,发现旱涝有迹可循;他在绳子上打结,一个结一头牛,两个结一袋粮,比一比就知道亏不亏;他步测田埂,把边界刻在木桩上,争执就少了;然后,“氓之蚩蚩,抱布贸丝。匪来贸丝,来即我谋。”
慢慢地,大家都学会了计算,并协调出了统一的算法。历法是对时间的计算,货币是对价值的计算,法律是对行为的计算。今天的天气预报、出行导航、基因测序、央行的利率决议,都是试图在巨大的不确定性中,用计算坍缩出一个确定性。
科幻作品里常常将高等文明定义为"低熵体"。因为熵是衡量混乱程度的物理量,熵越低,代表越有序。而高等文明拥有悠久的历史,灿烂的文化,井然的秩序,明确的社会分工,这些都是"低熵"的体现,是意义的富集。而这些意义的构建,都离不开计算。
可计算到底是如何发生的?从绳子上的结到案上的算盘,从“文王拘而演周易”到钦天监"璇玑玉衡,以齐七政"......从古至今,计算的载体很多,却万变不离其宗——把信息编码进物理状态,利用物理过程逼出结果。
回顾这些载体,绳结算得慢,算盘快一些,真正让算力指数爆炸的,是在第三次科技革命中登场的集成电路。自从我们这个专业诞生,人类所掌握的算力经历了半个世纪的指数爆炸,文明的形态也由此发生了翻天覆地的变化。今天手机拍一张照片,背后跑几十亿次运算;高铁调度系统同时协调几千列列车的交汇;天气预报把整个大气层的流动装进方程,就能算出三天后哪片云会变成雨。
如果说计算机的同学研究如何用计算解决问题,我们则是在研究计算本身——信息如何编码,用什么载体计算,如何组织计算过程。接下来要介绍的将近二十个科研方向,无外乎这三个问题。
用什么来承担计算
从模拟信号到数字信号
要计算,先得有个东西来承载信息。
最早的办法是在物理世界里留下痕迹。绳子打个结,一个结代表一头牛;泥板上刻一道楔形印记,代表一笔债;纸上写一个"5",代表一个数量。从绳结到文字到数字符号,载体在变,但都是在试图把信息固定在某种物理形态上。
到了近代,人类发现了一种更快的载体来承载信息——电。电压的高低可以代表数值,电流的通断可以代表状态。电信号跑得快、传得远,比在纸上写字强太多。然而,自然的电信号是连续的。电压不会只取 1V 或 2V 这样整齐的值,它可以是 3.1415926V,也可以是 1.14514V。我们中学物理所学的电路,就是如此。
像这样用连续变化的物理量来承载信息的信号,叫作"模拟信号(analog signal)"。黑胶唱片就是模拟信号的典型。它用沟槽的形状,精确地记录每一个音符的调值与响度。但像这样的模拟信号有一个绕不开的问题——噪声。黑胶唱片一旦磨损,音质就会不可逆地劣化。这是模拟信号的连续性的导致的,每一个值都是合法的,一个 0.9V 的电压,我们没有办法判断它到底本来就是 0.9V,还是 1V 的电压加上 -0.1V 的噪声。
解决这个问题的办法,就是在连续的电信号里预留一些区间来抵御噪声。电路中的电压依然是连续的 0~1V,但我们在接收端只承认两个状态:0V和1V。如果我接收到一个 0.3V 的电压,那我就认为我实际上接收到的是一个 0V 的信号,只不过在传输过程中受到了 +0.3V 的噪声;如果是0.8V,那我就认为是 1V。这样做虽然使得信息密度大大减小:一根导线只能传递2个状态,但却极大提高了可靠性。只要噪声不过分大,我们就不用管了。这就是"数字信号(digital signal)"。
今天我们手机里存的音乐就是这么做的。同一首歌,不再是一条连续的沟槽,而是一长串数字。播放时这串数字被还原成连续的电压,再驱动耳机振膜。
用数字信号进行二进制计算
从模拟信号到数字信号的转变,不只改变了音乐的存储方式,也改变了计算。
早期的电子计算也是模拟的。运算放大器把电压当数值,电路本身就是算式——两个电压叠加(V₁ + V₂)就是加法;一个电阻(V = I × R)完成一次乘法;电容上的电压随时间积累(V = ∫I dt / C),自然完成积分。但模拟计算面临和黑胶唱片同样的困境:噪声会累积。每经过一级电路就叠一层误差,十级还能忍,一百级就面目全非。所以模拟计算能解微分方程,但造不出复杂的通用计算机。
数字信号的计算思路则完全不同。它只用 0 和 1 来承载信息,而这就是二进制(binary)。数字信号的计算方法,本质上就是二进制的运算。
二进制如何运算呢?1703 年,莱布尼茨(Leibniz)发明了二进制。一百多年后,布尔(Boole)定义了二进制的计算方法,它为二进制0和1赋予了逻辑意义——1表示命题为真,0表示命题为假。在此基础上,他又定义了"与(AND)""或(OR)"“非(NOT)”三种逻辑运算,这三个运算其实就是高中数学集合运算的"交""并""补"。
如何用二进制的逻辑运算来实现十进制的四则运算呢?首先,已知二进制与十进制可以互相转换;再者,二进制的加法只有四种情况:0+0=0,0+1=1,1+0=1,1+1=10(逢二进一,就像十进制里 9+1=10)。这四条规则,都可以用逐位的与、或、非来表示。减法也一样。有了加法就能做乘法,除法稍微复杂点,但也能做。如此一来,二进制就成为一个完备的数制,可以作为十进制的平替。
把二进制映射到电路上
现在,我们已经有了信息的载体——数字电信号,有了运算的规则——二进制,离完整的计算系统还缺一样东西——计算的载体。
1937 年,21 岁的香农(Shannon)在他的 MIT 硕士毕业论文补齐了这个空白。他将二进制的布尔代数(Boolean algebra)映射到了电路上。两个开关串联,两个都闭合才通电——与;两个开关并联,任意一个闭合就通电——或;一个常闭开关,通电时断开——非。串联、并联,高中物理最基础的电路结构,就能实现二进制运算。我们只要把现实中的十进制问题转为二进制,再交给电路运算,就能获得答案。
同样在那段时间,在德国,康拉德·楚泽(Konrad Zuse)造出了第一台可编程的二进制计算机 Z3。艾伦·图灵(Alan Turing)则从理论上证明:任何可以被明确定义步骤的计算,都可以由一台足够简单的抽象机器完成。
不同的人,在差不多的时间,从不同的方向尝试使用电路来进行自动化的计算。于是,人类三百年的数学和物理发展,在此交汇。
不过,此时距离高效的电路计算,还有一个巨大的gap——成本。从前用来计算的载体是继电器或真空管,继电器太慢,真空管太大太脆弱。科学家剩下的任务,就是找到一种新的材料来制作电路。这个新的材料要求非常苛刻,它要能够把电路做得足够小、足够快、足够省电,且能够大规模集成,以便执行复杂的计算。这个看似不可能的任务,在1947年被贝尔实验室攻破了。
他们给出答案是硅(silicon)。
硅的黄金时代
硅与集成电路
二战期间,美国宾夕法尼亚大学受到军方的委托,计划研制一台能够快速且精确地计算导弹弹道的机器。研究人员秘密工作了数年,直到战争结束,才在 1946 年 2 月14 日,宣告研发成功。世界第一台通用电子计算机——ENIAC问世。

ENIAC(1946 年):占地约 170 平方米、重约 30 吨,由近一万八千个真空管构成,图为操作员正在为其重新配置线路。美国陆军照片
虽然 ENIAC 拥有很强的计算能力,但它的缺陷也相当明显。ENIAC 占地面积 170 平方米,相当于两间教室;重约 30 吨,相当于六头大象。此外,它的建造和运转成本也极其高昂。当时单单把这台机器造出来,就花费了将近五十万美元(相当于如今的六七百万美元),其在正常运转时的耗电量也极高。据传它每次一开机,整个费城西区的电灯都会黯然失色。更要命的是,ENIAC 的运转还非常不稳定,最坏情况下每过十五分钟就会有一个真空管(vacuum tube)因过热而爆掉,导致整台机器宕机。可以说,在当时,没有国家级的力量,不可能造出一台计算机。
然而,到了 1996 年,在 ENIAC 诞生五十周年之际,宾夕法尼亚大学推出了一颗长 7.44 毫米、宽5.29 毫米的芯片。这颗芯片实现了ENIAC 的全部功能,却比一枚一角硬币还小。

1996 年,宾夕法尼亚大学为纪念 ENIAC 五十周年制作的「ENIAC-on-a-Chip」:芯片仅 7.44 × 5.29 毫米,比左侧一枚一角硬币还小,却实现了整台 ENIAC 的全部功能。藏于美国计算机历史博物馆
五十年的时间,计算机从两间房变成一个指甲盖,发生了什么?
1947 年的圣诞前夕,在美国贝尔实验室中,威廉·肖克利(William Shockley)、约翰·巴丁(John Bardeen)和沃尔特·豪泽·布拉顿(Walter Houser Brattain)三位年轻人成功发明了晶体管(transistor)。它们的功能与当时计算机所使用的真空管类似,这让科学家开始思考是否有可能使用晶体管代替真空管来制造计算机。只不过,当时的晶体管工艺尚不成熟,无论体积、成本还是功耗,相比真空管都没有太大优势。于是科学家们又孜孜不倦地研究了十年,直到集成电路的横空出世。
![]()
晶体管的三位发明者——约翰·巴丁、威廉·肖克利、沃尔特·布拉顿(摄于 1948 年贝尔实验室)。三人因发明晶体管共同获得 1956 年诺贝尔物理学奖
1958 年 9 月 12 日,德州仪器的一个工程师杰克·基尔比(Jack Kilby),成功在一块单一的半导体(semiconductor)材料上成功雕刻了整个电路,称为"集成电路(Integrated Circuit)",后来它有个更大众化的名称——"芯片(Chip)"。我们高中学的电路,电源、电阻、电容、电感都是一个个分立的器件,需要用导线连起来,这叫"分立器件"。而集成电路的思路,是直接在一块材料上,把所有的电路元器件都雕刻上去,再沉积金属完成互连。这样一来,电路的体积大大缩小。无论是制作成本,还是体积功耗,基于集成电路制作的晶体管都远远小于传统的真空管。

杰克·基尔比与他发明的集成电路:手中一小片半导体上集成了完整电路,身旁是放大后的电路版图。1958 年他在德州仪器造出第一块集成电路,从此开启了「芯片」时代,并因此获得 2000 年诺贝尔物理学奖
后来,科学家找到了最适合的半导体材料——硅。硅有着独特的掺杂特性,掺什么杂质、掺多少,决定了这块硅是否导电、电阻多少,这使得用硅制作的晶体管开关高度可控。而硅的氧化层(二氧化硅)天然致密,几个纳米厚就能隔绝电流,因此它可以让开关可以做到极小而不漏电。此外,硅是地壳里第二丰富的元素,沙子里到处都是,这让硅的成本低到每个人都用得起。
从此,硅与集成电路强强联手,让计算机的体积大幅缩小,性能突飞猛进。结合之前提到的二进制与电路,我们已经有了一套高效的自动化演算系统。一个现实问题,只要能够数学建模,我们就能将其二进制化,然后交给芯片进行高效计算。
所谓芯片,其实就是赛博算盘。算盘用算珠来存储和计算,芯片用的是电子。
摩尔定律
1971 年,英特尔用这种材料做出了第一颗微处理器 4004:2300 个晶体管,指甲盖大小,取代了一整柜子的逻辑板。之后整个行业就坐上了火箭。1981 年,IBM 推出个人电脑,计算从实验室走进了办公室。1989 年的 486 处理器装了 120 万个晶体管,配上 Windows,让不懂编程的人也能用电脑。2007 年初代 iPhone 发布,消费者口袋里的算力超过了 1969 年把人送上月球的整个阿波罗计划。今天一颗手机处理器里超过 100 亿个晶体管。从 ENIAC 到智能手机,"旧时王谢堂前燕,飞入寻常百姓家"。
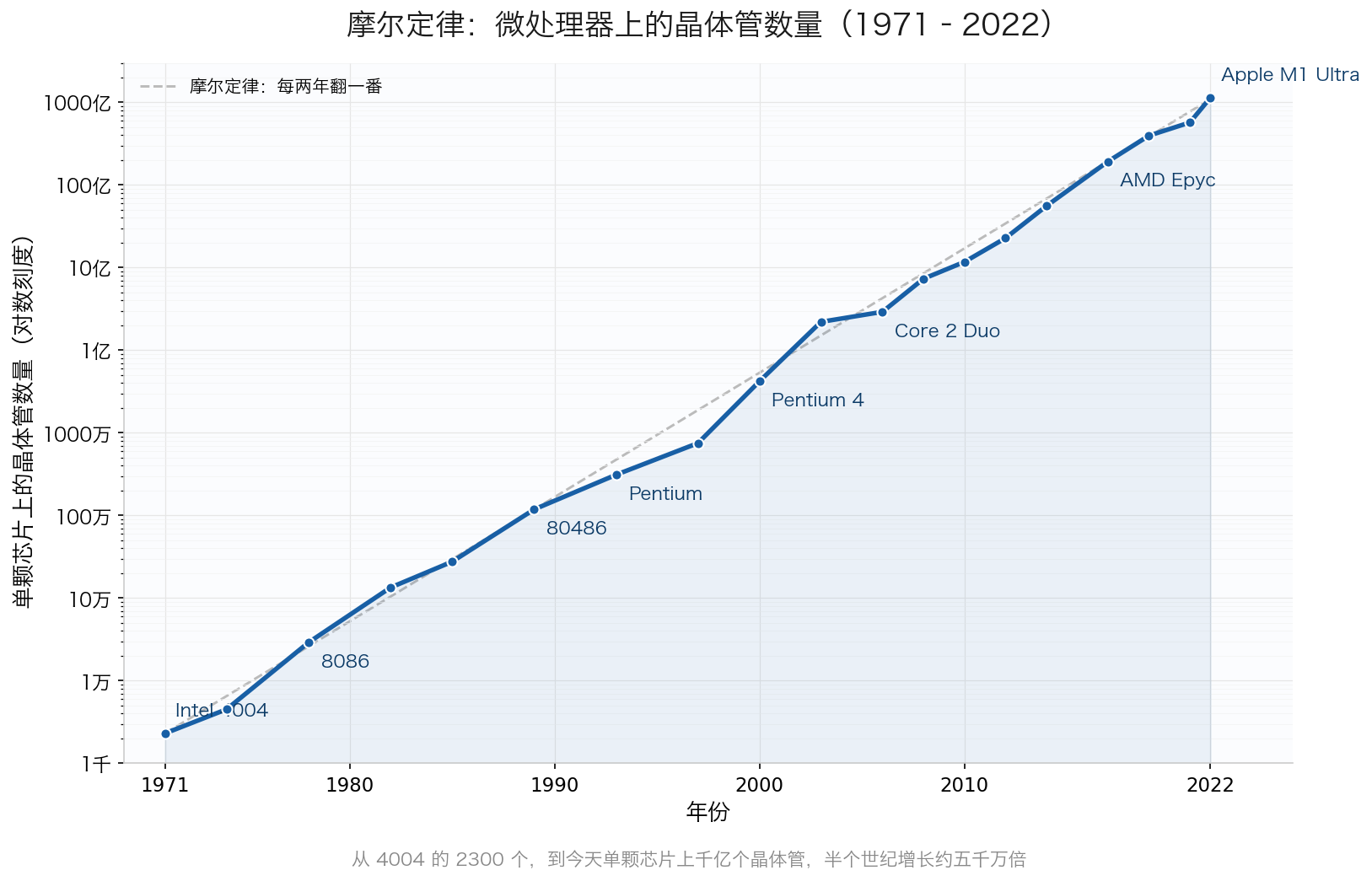
摩尔定律:单颗微处理器上的晶体管数量(1971–2022),纵轴为对数刻度。从 1971 年 Intel 4004 的 2300 个,到 2022 年 Apple M1 Ultra 的约 1140 亿个,半个世纪增长约五千万倍;虚线为「每两年翻一番」的理论参考线
从 2300 到 100 亿,这条曲线持续了半个世纪,就是后来人们说的摩尔定律(Moore's Law)。它背后是半导体器件与先进工艺的不断演进。这个方向的核心问题是:怎么把晶体管做得更小、更快、更省电?早期的晶体管是平面结构,栅极从上方控制下面的沟道,像一扇盖在水渠上的闸门。到了十几纳米的尺度,这个结构漏电越来越严重——闸门盖不严了。于是研究者把沟道竖起来,做成一片"鱼鳍",让栅极从三面包裹住它,控制力更强,这就是 FinFET。现在最前沿的工作是把鱼鳍进一步拆成一圈一圈的纳米片,让栅极从四面包住沟道。每一代新结构都是在跟量子效应较劲。晶体管越小,电子就越不按经典物理的规矩走。每一代光刻机的波长也要缩短一截,从紫外到深紫外再到极紫外,每一轮升级都是材料、光学和精密制造的极限挑战。
晶体管越做越多,设计越来越难。一颗 4004 的版图,一个工程师趴在图纸上画几周就能搞定。到了八十年代,几十万个晶体管的版图要铺满整面墙,画完把图纸裁好贴在胶带上送去制版。这种古早的芯片生产过程就叫 tape-out,今天芯片行业还在用这个词来指代流片。当电路来到几十亿个晶体管级别,靠手画已经完全不可能了。
于是我们有了 EDA 与设计自动化。EDA,全称 Electronic Design Automation,即电子设计自动化。这个方向做的事是开发算法,让计算机来设计芯片。工程师用硬件描述语言写出想要的功能,EDA 工具负责把这段描述翻译成一个可以送去制造的版图。几十亿个器件放在哪,线怎么走,信号能不能在规定时间内到达,全部由 EDA 完成。没有 EDA,摩尔定律早就停止了,因为电路的规模早就复杂到无法单靠人力来设计。
过去几十年,整个世界的运转方式被摩尔定律这条指数曲线改写了。但指数增长是有尽头的。
Party Is Over?
摩尔定律的思路是几何缩放——把晶体管做小,在同样面积里塞进更多开关。这条路跑了半个世纪,正在逼近原子的极限。硅原子直径约 0.2 纳米,今天的晶体管只有十几个原子宽,尺寸上已经快到同一量级。当绝缘的氧化层薄到几个原子时,电子会直接隧穿过去,开关即使关着,也会发生漏电。此外,每一次制程演进,都伴随着更加高昂的生产成本,带来的性能提升却有限,节点步进的性价比越来越低。
2026 年 5 月,华为在 ISCAS 会议上发布了"韬(τ)定律",提出了另一个维度:与其继续缩小空间,不如压缩时间。信号在铜线里传播需要时间,数据从内存搬到处理器需要时间,芯粒之间通信需要时间——τ 是时间常数,在计算系统的每一层,都有压缩 τ 的空间。
最直接的瓶颈在芯片之间的连线上。铜线有电阻,我们高中物理学过焦耳定律(Joule's law):Q = I²Rt,电流越大热量越多。数据量爆炸式增长,铜线上的信号切换越来越频繁,发热越来越严重。频率推到几个 GHz 之后,趋肤效应(skin effect)让铜的有效电阻进一步上升,信号衰减加剧,线与线之间串扰。光子不一样——不带电荷,没有 I²R 的损耗,不发热,带宽天然大。你家里的宽带可能已经用上了光纤,道理一样。光电子与硅光集成要做的是把光通信搬到芯片的尺度上:在硅片上做出光波导、光调制器、光探测器,让芯片之间的对话从电切换成光。挑战在于光学器件天然比电子器件大得多——光的波长是微米级的,晶体管是纳米级的——怎么做小、做兼容、把每比特能耗压下来,是核心的工程问题。
信号传得更快了,但芯片本身做不大。一方面是因为光刻机每次曝光的面积有上限(叫光刻场),另一方面是因为芯片越大,越容易碰到缺陷,良率随面积指数下降。如今的先进封装与异构集成换了一个思路:不再追求把芯片做大,而是做几颗小芯片,然后在封装层拼起来。芯粒(Chiplet)架构把 SoC 拆成计算、IO、存储芯粒,各自用最合适的工艺制造,通过硅中介层以微米级间距互连。三维堆叠更进一步——把存储直接叠在计算上面,数据走几百微米的垂直通孔而不是绕几厘米的平面走线,互连距离缩短几十倍。τ 定律的核心技术"逻辑折叠"就在这一层:把数字、模拟、存储电路分布在垂直堆叠的有源层上,在同一工艺节点下密度提升 55%、能效提升 41%。不靠更先进的光刻机在平面上把电路做小,而靠立体结构压缩信号走过的距离和时间。但芯片叠起来之后散热变难——底层被上层盖住,热往哪走?芯粒间的互连速度怎么逼近片内?这些是这个方向正在攻克的问题。
互连和封装解决的是信号“怎么跑得更快”。但还有一层时间浪费,不在传输上,在计算的组织方式里。从2004 年英特尔取消了 Tejas 的处理器的研发开始,芯片的工作频率就基本没有再往上增长了。原因还是刚刚提到的摩尔定律瓶颈,晶体管越做越小,栅极氧化层薄到只剩几个原子,电子开始发生量子隧穿(quantum tunneling),导致漏电。晶体管即使不工作也在发热,而要提高频率,晶体管就得切换得更快,功耗跟着飙升。漏电的热加上提速的热,超过了芯片能散掉的极限。频率再往上推,芯片就烧了。
因为这个问题的存在,处理器架构与编译系统应运而生。不靠更快的时钟,怎么让计算更快?一条路是并行——把一个核拆成多个核,把任务拆开同时跑;但任务怎么拆、数据怎么分、核与核之间怎么同步,都是硬问题。另一条路是专用化——通用处理器什么都能算但什么都不够快,为特定任务定制硬件,以牺牲灵活性的代价把效率拉到极致,谷歌的TPU就是一个例子。此外,编译器的角色也越来越重:指令以什么顺序发射、数据在缓存层级间怎么调度,直接决定了处理器要等多久——同样的芯片,编译器不同,性能可以差好几倍。
在架构设计中,有一条独树一帜的路径——可重构计算与 FPGA 。它既不做通用也不做专用,而是做可变的架构。FPGA 的逻辑阵列可以重编程,让电路形状跟着问题走——今天跑图像处理是一种电路结构,明天跑网络协议变成另一种。不像通用处理器那样什么都做但不快,也不像专用芯片那样只做一件事。硬件本身是软的。
以上两个方向都只是在让处理器算得更快,却没碰到一个更本质的问题。如今我们主流的芯片架构,无一例外都是“约翰·冯·诺依曼(John von Neumann)架构”。这是祖师爷冯·诺依曼在1945 年提出来的一个经典架构,典型特征就是"存算分离"。数据平时放在存储器,要运算时搬到处理器进行运算。这样做的好处是存储器和处理器可以分开设计,坏处是处理器每做一次运算都要去存储器跑一个来回取数据。这趟旅程不产出任何结果,却实实在在地耗时耗能。训练大语言模型(LLM)时,接近七成能耗花在搬数据上,真正做乘加的只有三成。
于是,在AI时代,存算一体与近存计算走了一条更具颠覆性的道路。这个方向摒弃冯诺依曼架构,把计算塞进存储器,在存储器里面或附近做计算。一条典型路径就是依靠一种叫忆阻器(memristor)的器件。用该器件的电阻值存权重,输入电压,输出电流,利用欧姆定律(I = VS)直接完成乘法。当然,这只是存算一体的一种实现方式,这个方向还有很多个细分流派。值得注意的是,刚刚介绍的这种方法使用的是模拟运算(欧姆定律),信号编码在连续的电压和电流里。在计算领域被数字电路统治几十年后,模拟电路开始有回归的趋势。
摩尔定律放缓之后,进步没有停止,只是从缩小空间转向了压缩时间。但到这里,所有的优化仍然在同一个框架内——经典的、基于 0 和 1 的计算。接下来的方向,则是横向扩展计算的边界,让计算深入到物理世界的方方面面。
计算触碰世界
我们对着手机说一句话。声波压在一片振膜上,振膜只有几百微米宽,随声压上下起伏,起伏又变成一段微弱的电压波动,供芯片处理。这片振膜属于一个 MEMS 麦克风。和它一起藏在手机里的,还有感受运动的加速度计、感受旋转的陀螺仪、感受气压变化的气压计。
MEMS 与微纳传感器研究的正是怎么在硅片上造出这些微型机械结构,让它们对力、声、压做出响应,再变成电信号。尺寸缩到微米级之后,热噪声和机械噪声会淹没信号本身。怎么在极小的结构上维持足够的信噪比,是这个方向最核心的挑战。
MEMS 输出的是连续变化的模拟电压,而处理器只认 0 和 1 的数字信号。在数字电路统治的几十年间,模拟电路并没有消失,它退到了数字和物理世界之间的接口上,占据了一席之地,这便是模拟与混合信号 IC 的研究领域。手机内部的数字内核用 0 和 1 飞快地算,而手机和外界打交道的每一个出入口,你说的话、拍的照片、收发的射频、跟电脑对拷数据的高速总线.....全是连续变化的模拟量。模拟与混合信号 IC 就是连接这两个世界的电路。
最典型的是 ADC 和 DAC。ADC 把连续电压切成比特送进数字世界,DAC 把结果还原成扬声器能推动的声波。但这只是冰山一角。手机里管供电的 PMIC、处理声音的音频 Codec、把摄像头每个像素的电荷读出来的电路、以每秒几十 Gb 收发数据的高速串行接口(SerDes)......每一个都是独立的混合信号子系统。它们也是整颗芯片里技术难度最高的部分。
声音进来了,处理完了,还得传出去。射频与毫米波 IC 把比特调制到载波上,变成电磁波从天线辐射出去,以光速飞到几百米外的基站。从 2G 的几百 MHz 到 4G 的几个 GHz 再到 5G 的毫米波,频率越高能用的频谱越宽,塞进去的数据越多。但频率高了信号衰减也快,器件的寄生效应更难控制,天线尺寸和波长绑定。每一代通信标准都意味着射频电路要从头设计。
信息跨越了空间。但计算要真正作用于物理世界,光传信号不够,还得有力量。电动车的电机不会自己转。需要电池输出几百伏直流电,逆变器把它变成交流电驱动电机,开关管在高压下每秒切换几千次。硅做这件事力不从心。它的禁带(bandgap)太窄。禁带是电子从"不导电"跳到"导电"要跨过的能量门槛,硅的门槛只有 1.1 电子伏特。电压一大,电子被强行拽过去,开关关不住,能量白白变成热。碳化硅(SiC)的禁带是硅的三倍,氮化镓(GaN)更宽。门槛高了,开关关得严,损耗小,耐高温。电动车从 400V 切到 800V 充电翻倍,靠的就是碳化硅。功率半导体与宽禁带器件研究的是怎么把这些新材料做成可靠的量产器件。因为碳化硅晶体生长比硅困难得多,缺陷会导致高压下失效;氮化镓散热是难题。这些器件是计算伸向物理世界的肌肉。数字信号决定什么时候开关,功率器件把这个决定变成几百伏几百安的动作。
感知声音、翻译信号、传递信息、驱动电机......这些接口让计算能听、能说、能出力。但还有一个接口,野心更大,试图让芯片与生物连接,这便是生物电子与脑机接口。
硅用电子通信。神经元用离子和递质通信。两套完全不同的语言,之间没有现成的词典。生物电子与脑机接口要在硅和神经之间搭翻译层:电极要小到不损伤脑组织,要稳定到在体内工作几年不退化,要灵敏到在电化学噪声里分辨出单个神经元的放电,还不能被免疫系统当异物排斥。这并不是在感知外部世界,而是让一个计算系统直接读写另一个计算系统的内部状态。
当芯片成了银行、电网、国防的底层之后,一个新问题冒出来:你凭什么相信一块芯片是可靠的?软件加密做得再好,也假设了底下的硬件可信。可硬件本身会泄密。计算的物理过程,会泄露计算的内容。比如芯片做加密运算时,功耗会随密钥的每一位微微起伏,拿示波器量一量功耗曲线,就能把密钥一位一位推出来。这叫侧信道攻击(side-channel attack)。此外,处理器为了跑得快,会提前猜测、抢先执行后面的指令,猜错了就丢掉;可这些被丢掉的运算在缓存里留下了痕迹,攻击者顺着痕迹就能读到本不该看到的数据。为了快而做的优化,反倒成了漏洞。
硬件安全与可信计算研究的就是当攻击者能碰到计算的物理层面,怎么守住计算的保密性与安全性。一个办法是利用制造时的微小偏差,给每块芯片生成一个无法复制的"指纹",用来证明它的身份;还有一个办法是在芯片里划出一块隔离区,敏感运算只在里面做,外面碰不到;还有从开机第一行代码起逐级验证,确保整条启动链没被篡改。还有一种思路更釜底抽薪。与其费力守住计算的物理层面,不如让数据自己就读不懂。同态加密(homomorphic encryption)让计算可以直接在密文上进行——你把加密后的数据交给一台完全不可信的服务器,它在不解密的情况下算出结果,结果还是密文,只有你能解开。从头到尾,服务器没见过你的原始数据。代价是慢,在密文上算一次可能比明文慢上千上万倍。怎么用专用硬件把它加速到能用,是这个方向最前沿的挑战之一。
计算的革命
最近十几年,大家可能注意到一件事:电子产品不再像之前那样日新月异了。2016年的电子产品和2006年的相比像是两个时代,而2026年的产品比起2016年却没什么变化。手机、电脑、电视、电器几乎都是如此。
这就是摩尔定律放缓在日常生活里的投影。《三体》里人类的基础科学被"锁死",现实中芯片的性能被底层物理锁死。算力不再指数增长了,第三次科技革命到此也终于迎来了尾声。
但就在这个“好像要停了”的年代,算力的量变引发了计算范式的质变。一场革命,引发了另一场革命。
2012 年,多伦多大学的亚历克斯·克里热夫斯基(Alex Krizhevsky)提出 AlexNet,一举拿下 ImageNet 图像分类冠军——AI 来了。在此之前,计算是演绎的:人写规则,机器执行。AlexNet 之后,规则从数据里长出来了——没有人告诉它猫长什么样,它自己从一百万张图片里学会了。但这把火真正烧到每个人面前,是十年之后。2022 年,ChatGPT 发布。计算,这个抽象的物理过程,居然能用人话跟用户对答、写代码、改文章、做心理咨询。AI 从实验室里的论文,变成了每个人口袋里的工具。
这场AI革命的能量很快溢出了技术本身。2023 年初,很多经济学家预测全球会在一年内迎来一场经济衰退。结果它没有如期到来。不少人把功劳记在 AI 头上。芯片、数据中心、电力的投资狂潮,硬生生把本该到来的衰退往后顶了几年。
集成电路学科在AI时代的机会是什么呢?那就是AI 算法与系统,或称AI Infrastructure。AI的算法与以前的计算任务大不相同,AI的核心是神经网络(neural network),而神经网络的核心运算是大规模矩阵乘法(matrix multiplication),需要几千个计算单元同时工作,需要带宽极大的内存喂数据,需要多颗芯片高速互连协同训练。传统的CPU擅长处理串行任务,执行AI任务效率很低。所以我们需要根据算法来设计硬件,或者调整算法来适配硬件,这就是软硬件协同设计,一个非常重要的设计理念。什么样的数据流架构最适合注意力机制?稀疏计算能不能跳过无用的零值?训练和推理该不该用不同精度的数值?在算法和硬件之间架起一座又一座桥,就是我们做的事情。
AI 能认出猫的照片,但摸不到猫。它活在屏幕后面,处理的是数据,不是现实。具身智能把计算带进了物理世界。自动驾驶车在雨夜的路口判断行人意图,机械臂在流水线上抓取形状不一的零件。环境不可完全建模,信息永远不完整,决策不可撤回。机房里的模型可以跑十遍挑最好的答案;路上的车只有一次机会,然后承受物理后果。怎么在感知有噪声、模型有误差、后果不可逆的条件下快速做出足够可靠的决策?没有哪个数据集能完全覆盖这个问题,也没有哪个仿真器能替代真实世界的复杂性。但研究具身智能的人还是迎难而上。
上层在革命,底下也暗流涌动。
AI 不仅引爆了应用层的变革,它还打开了一扇之前关着的门。最开始我们讲过,模拟计算输给数字,根子在噪声——精度不够。但神经网络天生对精度不敏感:32 位浮点砍到 8 位甚至 4 位,模型照样能工作。精度要求一降,模拟计算最致命的弱点就不再致命。这也是为什么存算一体里能让模拟运算回归。
然而现在的AI还是差强人意。大脑仅用 20 瓦的功耗就能在室温下完成人类全部的感知、语言、推理和运动控制,AI 用几十亿参数和几百瓦的功耗却还做不到。能不能模仿大脑来设计芯片?这就是类脑芯片做的事。大脑神经元只在收到脉冲时才激活,其余时间几乎不耗能。信息不编码在电压的高低里,而是在脉冲的时序里。神经突触既存储又计算,且本质上是模拟计算,突触电位连续变化,脉冲时序连续分布。类脑芯片提取这套计算策略,试图用半导体工艺复刻我们的大脑。脉冲神经网络(spiking neural network)、忆阻器突触,都是这一方向的结晶。
如果说,类脑芯片只是在计算架构上做文章,本质上还是用电信号做计算,那么光计算与量子计算则彻底颠覆了芯片的底层物理机制。神经网络推理的核心是矩阵乘法 y = Wx——把输入向量乘以权重矩阵得到输出。光学干涉天然就能完成这件事。把输入向量的各个分量分别编码成不同光路上的光强或相位,让这些光路通过一个由分束器和相移器构成的网格,光在内部干涉叠加,从输出端口出来的每一路光强就对应矩阵乘法的一个结果。光计算的计算功耗低,频率高,且可以用不同频率的光同时计算,并行度高。但问题在于精度低、算子单一、光电转换功耗高、光器件的集成度也差。这是目前光计算研究者在攻坚的瓶颈。
量子计算与量子芯片则扎根量子物理。经典比特是 0 或者 1,量子比特(qubit)可以同时处于两者的叠加态(superposition)。多个量子比特纠缠关联,干涉效应让错误的计算路径相消、正确的路径增强。对特定问题——大数分解、分子模拟、组合优化——量子算法需要的步骤数可以指数级少于经典算法。但量子态极其脆弱,环境里任何不受控的扰动都会破坏叠加。研究者面对的核心问题是:用什么物理系统做量子比特最稳(超导、离子、光子还没分出胜负),又怎么用一堆会出错的物理比特纠错出一个可靠的逻辑比特?今天的超导量子芯片要在接近绝对零度里工作,能不能放松这一条件?
类脑芯片、光计算芯片、量子芯片,它们都在寻找硅和经典逻辑之外的载体来计算。上层的 AI 革命在重新定义计算能做什么;底层的探索在重新定义计算可以是什么。两层同时发生,互相拉扯,互相加速,是这一轮AI革命最底层的推动力。
计算的本质
文章开头说过,计算无非是把信息编码进物理状态,再用物理过程逼出结果。它的本质是什么呢?我想是用物理熵的增加换取信息熵的减少。计算离不开物理过程,要实现信息熵的减少,增加一份确定性,就必然要消耗能量,产生废热。
1961 年,罗尔夫·兰道尔(Rolf Landauer)把这件事写成了一条精确的定律:每抹去一个比特,至少释放 kT·ln2 J 的热量。数值极小,却是不可逾越的底线。信息,有物理的重量。这笔代价,不同计算载体的支付方式不一样。算盘用机械位移付,大脑用电化学反应付,芯片用电子在掺杂硅里的流动付。而今天的芯片,离兰道尔的理论极限还差着好几个数量级,远没有做到最高效。也就是说,我们还有很长一段路要走。所以我们研究的问题,本质上就是用什么载体、以什么方式,能把计算做得更高效?以上介绍的十七个科研方向在用各自的方式回答这个问题。把开关做小,把信号变成光,把计算塞进存储器,把范式换成大脑,把基底换成量子。每一条路,都是在重新计算物理熵和信息熵之间的汇率。
一万年前田埂上那个农民不会想到这些。但他低头数雨水间隔的那一刻,做的就是同一件事。用一点物理代价,换一点对世界的确定。